Testing on the YAZ180 v1 , shown below, is now complete. I don’t want to use it for further driver and platform development, because the PLCC socket for the 256kB Flash is becoming worn-out.
It will continue to operate as an augmented Nascom Basic machine, with an integrated Intel HEX loader (HexLoadr) supporting direct loaded assembler or C applications.

YAZ180 v1 at full configuration.
The new PCB for the YAZ180 v2 has been ordered.
These are some screenshots of the new PCB.






Pi Day, March 14 2017.
After dwelling on the fact that the V2 PCB was really just a clean up the V1 PCB, with no additional features, I decided not to build the beautiful new PCBs that arrived today.
But rather, to create a new PCB with additional features.







When I originally designed the YAZ180 the breakout for the 82C55 was simply an interim design, to enable me to test the board. I was thinking of making an Arduino style pin-out, or something along those lines. But this is something much better.
Recently, after reading Paul’s page on interfacing an IDE drive to an 8051 microprocessor with the 82C55, I decided that adding IDE to the YAZ180 was a must-have feature.
So there is a new connector on the YAZ180 to break out the 82C55 pins, in IDE 44-pin 2mm format. I have not followed the design provided by Paul exactly. I’d note that his design and the earlier design by Peter Fraasse were specialist designs, which don’t support the generalised usage of the 82C55 chip, beyond the IDE functionality.
By the above statement I mean that in Mode 1 and Mode 2 for Port A and Port B, the PC2, PC4, and PC6 pins of the 82C55 device are designated registered strobe input pins /STB in input mode, or peripheral acknowledge /ACK in output mode. If an inverting output buffer is connected on these lines, then the registered input and output mode capability is lost. This would restrict the functionality of the 82C55 to simply Mode 0, being the mode that is used to create the IDE functionality.
As I’ve connected the three IDE address selection pins to PC2, PC4, and PC6, and these pins are not passed through an inverting buffer in the design, it is possible to use the 82C55 in any of its modes, and therefore to use the IDE 2.5″ 44-pin form factor to connect the YAZ180 82C55 ports to extension PCBs of any type or design.
As a connected IDE drive or other extension board may need to interrupt the CPU, I have connected the IDE INTRQ pin to the remaining inverting buffer to provide an input to the CPU on /INT0. As the /INT0 (or actually the INTRQ) input terminates on the IDE header, either a IDE drive through INTRQ, or either of the two 82C55 INTR pins, PC3 or PC0, can originate the interrupt.
I have reconfigured the Am9511A-1 to use the /NMI interrupt, as previously the /INT0 was configured.
The new YAZ180 v2 PCB has been ordered. YAZ180_v2_Schematic.
Happy Pi Day.
Update – RetroChallenge Day 1
I’ve decided to enter the RetroChallenge 2017/04 and my challenge is to read and write to an IDE drive using the newly configured IDE interface on the YAZ180v2. But before I can write the code for the IDE interface, there’s a bit of building and testing that needs to be done.
The new PCBs arrived a few days ago, and they look great. But Arduino Day and the first day of the RetroChallenge 2017/04, 1st April, seemed like a good day to lay them out.

New PCBs. 2oz Copper, 2mm thick. Opulent.
I was hoping to lay build several boards at once, but somehow I forgot that there was only one RAM and one FT245 device in my component stocks. That means that I had to satisfy myself with just one board for now.
Note the suitably Retro PowerMac (circa 2001) driving the layout guide screen.

Adhoc Workspace
This is the board just before cooking. Respect to anyone who notices the substantial noob layout mistake. Anyway, after a small smokey explosion, everything was rectified.

Two YAZ180 versions, side by side.
This is the finished build of the YAZ180 v2. Looks very tasty. Retro goodness.

Fully populated YAZ180 v2 PCB.
I’m still working on fixing an issue with my code, which I noticed when experimenting with the Am9511A APU, and inserting an Interrupt Jump Table. Basically, I’m getting jumps to odd or random locations, which is detected buy filling unused locations with 0x76, the HALT, OpCode. The most common address where the HALT is executed at is 0x00C3.
Previously, I’d been filling unused locations with 0xFF, the RST 38H OpCode shared with the INT0 location 0x0038, which was causing the APU to be triggered inappropriately. This issue has me snookered. I can’t move on, in the software sense, until it is resolved .
Update – RetroChallenge Day 8
Well this week was one of the most frustrating weeks ever, in terms of time spent vs. results obtained.
There are two major projects in hand. 1. Getting the YAZ180 v2 running, and 2. resolving the software issue plaguing my initialisation code.
Hardware issues
Bringing up a new piece of hardware is never easy. Initially, nothing can be trusted to work, and everything needs to be checked against the design, and then even the design checked for correctness. Bringing up the YAZ180 v1 was very time consuming, because I had to develop the PLD design during the process, as well as checking that all the hardware was sorking as it should. I thought that bringing up the YAZ180 v2 would be easy. Just solder it together and win. But it has not been so simple.
Essentially, after a week of working on this every evening, I don’t know why it is not working correctly. All the standard things, volts, clock, stuck address and data lines, etc are all working correctly. But it still doesn’t work. And, it may not be just one thing that is wrong, but if anything is not perfect it just won’t work.
After a few days of testing, I found that I’d programmed the PLD devices with an old version of the CUPL code. Nearly right, but not exactly right. Once I’d isolated that issue, by ensuring the new GAL devices worked perfectly in the V1 board, I thought it would be enough. But no. There’s still something wrong.
My current thought is that somehow, either electro-static damage or heat damage, the RAM is unreliable. But, I’m not sure enough of this to unsolder the RAM device and replace it. I’ll be spending this weekend on resolving this problem.
Software issues
Because of the effort I’ve been putting into resolving the hardware issues, I’ve not been able to solve the software issue apparent in the YAZ180 initialisation and serial code. I’ve documented the issue on Github.
My lesson learned is NOT to fill unused memory with 0xFF bytes. This causes RST 38H jumps to the INT0 location when the PC is incorrectly loaded, and can be very distracting. Best to fill unused memory with either 0x76 HALT bytes, to see where things became broken, or with 0xC9 RET bytes to just float over the underlying issue.
I’ll need to fix this properly, but it has consumed several weeks of effort, and I’m not much closer to resolution.
Update – RetroChallenge Day 10
The weekend was unkind, but today some new eyes (literally) have brought successes.
Hardware Issues
After doing quite a bit of further testing, I’m fairly sure that I’ve damaged the RAM and will need to replace it. So, I’ve ordered a hot-air solder gun. Should have had one for a long time. Finally, I’ve got a round-‘tuit. I’ll have to order some replacement components too, which will result in being able to make additional boards as well.
Software Issues
Finally, I’ve resolved my issue. What we had here was a classic “failure to understand”. Somewhat embarrassed to leave this here for Internet eternity.
- Z80 vectors are supported by a JUMP table.
- Z180 vectors are supported by an ADDRESS table.
Insert JP instructions into an address table and you will have a very very bad day.
Or in my case, quite a few of them.
This issue cost so much time. But at least on the up side, I’ve written robust Z80 and Z180 vector tables, improved my ASCI code, and cleaned up initialisation code, in trying to track this down.
Also finally, I now understand. Which is the entire point, anyway.
Update – RetroChallenge Day 17
Following up on the success of last weekend, I was hoping to have a lot of achievement to write about today. Unfortunately, it has been a grind this week too.
I have been distracted back into the original project that unearthed my previous software problem, and led me along the path to getting a much better understanding of the Z180 CPU, and then solving the issue. The original project was building an interrupt driven driver for the Am9511A-1 Arithmetic Processing Unit.
I’ve spent pretty much the past week on this code, and digging through it with a fine tooth comb. I’m now of a belief that my Am9511A driver code is correct, but my hardware is not correct and may never be correct.
The issue lies with the requirement for the Am9511A to have the Address lines and Chip Select signal remain valid for 30ns following raising of the Write signal. Unfortunately, the Z180 only maintains valid address lines for 5ns following Write. This means that writing to the AM9511A APU is very much a hit and miss affair, with miss being the most likely outcome. I’m still thinking about ways to bodge this to work. But, I think that it may just be too hard to get the old APU to work with a modern CPU. More on this later.
This week I’ll be working on the PaulMon IDE code, and migrating it from 8051 to Z80 nomenclature, and trying to get it to compile.
Update – RetroChallenge Day 21
Well the last couple of days have been exciting, as I found a way to make the Am9511A APU work. A hint from a fellow competitor (on working with the MC6809 CPU) inspired me to look further for information on options to fix the hardware interface.
The Z180 E CLOCK
The Z180 has an almost undocumented feature, called the E Clock. Yes, it is documented in datasheet that it exists, but there’s no real background that I can find as to why it exists, except that is for a Secondary Bus Interface. This pin and signal doesn’t exist on the Z80, for example. Anyway, since it has the same name as a signal on the MC6809, I thought it might be worth looking at it. It turns out that the E Clock provides a shortened version of the WR and RD cycles. Which is exactly what we need.
One caveat however, when running at doubled PHI rates (i.e. 1:1 PHI – CLK) the shortening of the E Clock signal is not sufficient to drive the APU successfully. At 18.432MHz, the PHI/2 timing is 27ns. Therefore, the minimum of 30ns between release of WR and CS is not always held. This means that we’ll need to keep the PHI at half CLK whilst using writing data into the APU. In practice this means that using the APU requires we cut the CPU clock by 50% or PHI/2 being 57ns, to ensure the trailing 30ns is provided.
Anyway. Good news. With the revised timing, the Am9511A-1 is working.
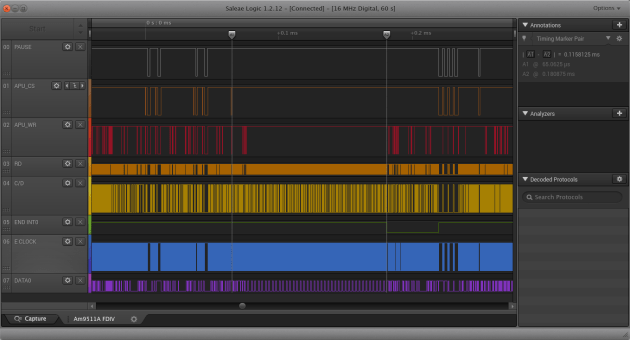
Am9511A APU Floating Divide in 115us
The E Clock is not an inverted signal, so to generate the active low APU_WR signal we have to first invert it, then OR it with the WR signal. For the purposes of testing, I’ve got a little breadboard with a GAL on the side, but later I’ll build a new PCB and add in a SN74LVC1G97 little logic device to provide the APU_WR signal.
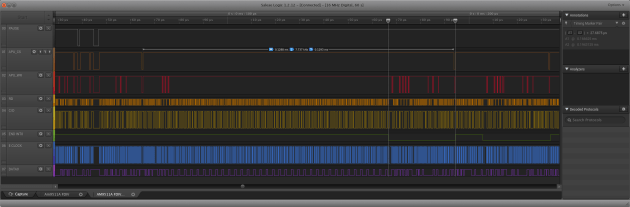
Am9511A APU FDIV PUPI command interval 128us
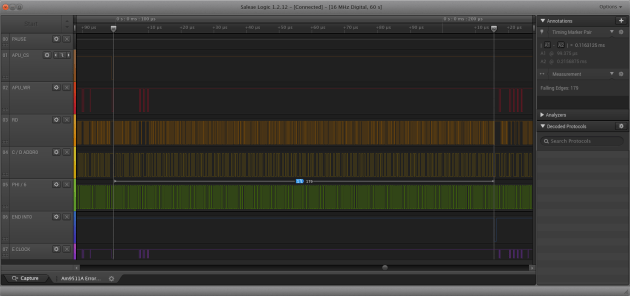
Am9511A APU FDIV in 179 Phi/6 Clock cycles
So now we see the Am9511A APU FDIV floating point divide takes about 101us to 115us when running at 1.536MHz, or from the datasheet 154 to 184 clock cycles. In 101us, the Z180 CPU at 36.864MHz produces 3,723 cycles. To produce a floating point divide using the Lawrence Livermore Library requires about 13,080 cycles, according to the AM9511A Floating Point Processor Manual by Steven Cheng. Therefore, we are still substantially faster than antique software on a modern Z180!
Update – RetroChallenge Wrap Up
Well the month of RC2017/04 didn’t go quite as planned. My original intention was to have the YAZ180v2 working very quickly, then get straight down to porting Paul’s IDE code from 8051 to Z180 to get the new IDE interface working. But, there were several speed bumps along the way.
Gaining an education
Since I just started on this whole Z80 processor and assembly language programming thing a few months ago, I don’t have a long history of coding to fall back on. I had written some code for the Z80 in the RC2014 hardware, which I then tried to use on the Z180 in the YAZ180. But, there is a subtle difference in “generation” between the way the interrupt vectors work across the two machines. Obvious, once you know about it but a real “time killer” if you don’t.
Firstly, filling unused space in your assembly program with 0xFF is a very dangerous thing to do in Z80 assembler, particularly if you don’t understand that 0xFF is the op code for RST38, which is a single byte jump to the same location as the Interrupt 0 in IM1 mode. It would make more sense to fill the unused space with 0x76, which is the HALT instruction, to trap an unexpected program counter value.
Look before you leap
Secondly, the interrupt vectors on the Z80 were designed to contain code, and the PC is just loaded with the address of the vector, and execution begins from there. So for an INT0 (or RST38) execution begins from 0x0038. But, the interrupt vectors on the Z180 are designed to hold an address. The difference being that an interrupt will load the PC with the contents of the two bytes at the vector, and then begin execution from there. I think this difference is a sign of the generational difference between the two implementations. One of the clearest differences I can find, anyway.
Timing is everything
One of the goals for the YAZ180 is to bring some old chips back to life, in a modern platform. Along with the TIL311, GAL16v8, and 82C55 devices, the Am9511A holds pride of place as the very first arithmetic processing unit ever made. I’ve invested far too much time in getting the Am9511A to work, but it is important to me that my project can make it work.
I believed that I had devices that were specified to run at 3MHz but which in fact didn’t. That may be incorrect. More likely was that I wasn’t driving them properly, because my timing was out. I will need to go back and test them all again.
Here the issue is that the Am9511A requires extended validity of data and chip select signal, following the validity of the write signal. At least 30ns is required. This is not provided by the Z180 in its normal timing, although in the configuration I have it, coincidentally because I’d buffered the data bus, it is nearly right. Only the chip select line was being incorrectly handled.
I was nearly giving up but then a tweet from a fellow RC2017/04 competitor gave me the inspiration to look further. It turns out that the Z180 has a secondary I/O timing signal called the E Clock. This signal is not present on the Z80, and as I didn’t understand its purpose I’d left it unconnected in the YAZ180.
Whilst the Zilog datasheets on the Z180 completely gloss over the purpose of the E Clock signal, by simply not mentioning it, the original Hitachi 64180 datasheets do mention it. The original purpose of the E Clock signal was to provide timing for “a large selection of 6800 type peripheral devices” including the “Hitachi 6300 CMOS series (6221 PIA, 6350 ACIA, etc) as well as the 6500 family devices”.
In summary, the E Clock provides a signal that is half a T cycle shorter than the write signal. It means that gating the write signal with the E Clock would allow me to release the APU write signal sufficiently early to maintain the extended chip select timing required. Basically, the APU won’t operate with a Z180 T Cycle any less than 60ns, or 16.6MHz. So in my implementation, the PHI clock will need to run at half speed or 9.234MHz, whilst the Z180 is using the Am9511A. Unless I cook up another plan.
Zapped
And the final note from this month is that I believe my very poor ESD protocol has led to the destruction of the SRAM on my YAZ180v2. Therefore I had to desolder it (and it looked so nicely done) to remove it, and order some new components.
Ordering new components is always a bit of a hurdle for me. I’ve collected quite a few things that I don’t use, so I tend to ration myself on purchases vs. progress. Finally, at the end of the month I ordered more components to build further YAZ180 boards, and some spare SRAM to enable me to repair the one I have made already.
It continues to amaze me just how much difference there is in the cost to build an Arduino AVR board (basically just a chip at the most essential level), vs something like the YAZ180. The YAZ180v2 bill of materials, excluding specials like the GAL16V8D, TIL311, and Am9511A devices that I have to find of eBay, comes to over $150 Australian!!! We need to export more coal, to get the AUD dollar back up there!
And that’s it for my RC2017/04 month. Soon as the parts arrive I’ll be completing the YAZ180v2, and then testing the IDE interface. I hope that will be done before the end of 2017/05.
Update – Post RetroChallenge
Well good news. The only issue was a bad solder joint on the new SRAM chip. Now the YAZ180v2 is running, and I can get onto translating the IDE code from 8051 to Z80.

YAZ180 with IDE drive attached.
I’ve sourced code from both PJRC in 8051 mnemonics for an 8255 PIO and from Retroleum in Z80 mnemonics for an 8 bit interface. Between the two of them, together with the examples from the OSDev Wiki, it should be easy to make a fairly robust implementation. And, on May 18th, the driver code was finally working.
Next activity is to integrate this into the z88dk, and then using the FAT-FS code from Elm ChaN, get the disks properly working.
Update – August 2017
Over the past few months progress has been made on various fronts with the YAZ180v2. Firstly, the IDE interface is fully working, and has been integrated into z88dk. Also, the issues with the Am9511A-1 APU have been resolved, and a working driver has been integrated into z88dk. While I still have to revise the C interface for these two pieces of code, because I’m still learning this, the development work is now done.
I am particuarly happy about getting the Am9511A APU working, as this was causing me the most technical difficulty, and stretched my understanding the most. I’m also happy that the capability in the Am9511A seems to be realised through performance improvements in arithmetic computation.
Over the coming months, I hope to resolve the remaining untested components in the YAZ180. These include the parallel programming interface, to allow the YAZ180 to be “cold loaded”, to protect against bricking the system, if a user doesn’t have a EEPROM or Flash writer. I’m still in two minds abou this feature, as the cost of the FT245 device and USB socket is about the same as a stand alone EEPROM writer, and the parallel programming interface consumes space that could be otherwise used for an SPI or USB interface, for example.
I also need to test the I2C interfaces, and debug the driver that I wrote back in May (still unused) to complete the feature set.
With this done, I’ve now done a new minor revision of the hardware, to clean up the issues that have been noted over the past months.
Open Issues
- APU – Gate E clock with WR to produce shortened APU WR
- NMI – remove this from the APU, and terminate high. Not CP/M compatible.
- INTO – reconnect it to the APU.
- 5V – Power inductor spacing.
Update – October 2017
Well, I fixed the issues and then convinced myself that there needed to be Yet Another feature added to the YAZ180, before I signed it off. So now, the v2.1 board has access to the Internet through an ESP-01S AT interface.

Building up this new board will be November and December’s activity, together with building a complete YABIOS (Yet Another BIOS) to make use of all of the features packed into the YAZ180 board. I’ll be picking the best bits, IMHO, from the Cambridge Z88, ZX Spectrum, and CP/M 2.2 – ZSystem to build a banking capable YABIOS, supporting 1MByte of address space.
Update – August 2018
I seriously need to write another blog on the YAZ180. But I guess the Github commits just speak for themselves. There are only three things left on the to-do list. 1. finish the firmware loading program. 2. rewrite the I2C interface. And 3. implement FreeRTOS as a hypervisor allowing multiple 60kB applications to run simultaneously.
Here’s a picture of an application, which was one of the early drivers for building the YAZ180, a mass-storage platform for my HP48 calculator.

YAZ180 communicating with HP48 using Kermit on ASCI1 (TTY).